
Bringing Back New Deal Local Labor History with AI
Here's how I used Claude Code to revive a decade's worth of midcentury issues of "Labor World," the newspaper of the Chattanooga Trades and Labor Council. It's now available to read online.


To help my own public power research and to scratch an itch in archiving historical materials, I’ve gone through the work of producing a digital archive of Chattanooga’s Labor World newspaper for the years 1929 to 1940. Labor World was published by the Chattanooga Trades and Labor Council, an affiliate of the American Federation of Labor, from 1915 to 1984. The archive is organized into PDF files by volume, each one indexed by issue number and date, which you can now read, download, and search through for free on Archive.org.
Warning: The rest of this post is a boringly detailed description of the process of procuring the raw microfilm scans and of the use of modern AI tooling — Claude Code — to refine them into the final, organized product. It’s intended to help labor historians and others understand how to use these tools as research assistants for their own archival projects, not just saving an incredible amount of time but accomplishing tasks one doesn’t know how to do otherwise.
The search for local public power history
From time to time I dig through historical newspaper archives when researching public power history, using subscription services like Newspapers.com. A recent interest of mine has been the history of public power in Chattanooga around the dawn of the Tennessee Valley Authority in the 1930s, and in particular the 1935 city election that ratified the bonds needed to initiate a public power utility. For that, the archives of the erstwhile progressive newspaper the Chattanooga News have proven invaluable. I’ll have more to say about that campaign in a future post.
When reporting on the public power campaign, the News periodically cited a publication called the Labor World, a local newspaper published by the Chattanooga Trades and Labor Council, itself a body affiliated with the American Federation of Labor. For example, on March 9th, 1935, under the heading “Labor World Indorses [sic] Public Power,” the News excerpted labor’s championing of public power:
The Labor World believes that organized labor will go down to the polls practically en masse and vote for the bond issue which will make possible the distribution of power by the people rather than by the Power Trust. The Labor World, mouthpiece of the Chattanooga Trades and Labor Council, calls on every working man and woman to go to the ballot box on March 12 and vote 'Yes'.
Very interesting! I wanted to learn more about Labor World and I definitely wanted to dig through the archives. But information about the 20th-century labor publication is hard to come by. A 2007 article in a local news outlet (and still available online!) offers a rare overview:
For seventy years, the Labor World newspaper kept Chattanoogans informed about the labor rights movement, and made sure that readers knew of the original significance of Labor Day. […]
Labor World was first published in 1915, and adopted the motto, “Devoted to the interest of all the wage-earners.” The biographies of each of its editors over the years show that the newspaper was headed by individuals who were writing from the perspective of being members, not spectators, in the labor movement.
The newspaper ran from 1915 to 1984 according to that article.
Where can one read archived copies of Labor World? According to WorldCat, only eight libraries have any copies, and each of them holds those copies only as physical microfilm, with no digital access.

{kind=link}
Among those libraries, the Tennessee State Library and Archive offers a microfilm digitization service: for $90 per reel of microfilm, they will scan every image in the reel and mail you a thumb drive with the files. So I ordered three reels of Labor World to be scanned and sent to me. Within a few weeks, I was the happy owner of a thumb drive with a decade of New Deal-era labor history.
My new digital copy of the Labor World consisted of 1,990 pdf files split across three folders for the three reels and named simply by sequence numbers. Each file contained a 300 dpi image in a “2-up” layout: each a scan from an open book, with left and right pages on either side of a spine. And there was no metadata to be found in any of them.
To be of real use to me, though, I needed these two-thousand images of Labor World to be indexed by volume, issue number, and date. All the text should be searchable, too, at least to the extent that its sometimes shabby source would allow. That required three phases of processing:
For starters, I needed to split the left and right page images from each 2-up source image so that my final PDFs would have a single printed page per PDF page.
With each individual page now a separate file, about four-thousand of them, I needed to detect which ones represented the front page of an issue. Each front page needed to then be visually scanned to detect the volume, date, and issue number in the horizontal strip below the masthead. That would tell me which issues I had and give me a sense of how complete the archive actually was.
Finally, I wanted to run optical character recognition (OCR) on the images in order to extract the text and embed them in the final PDFs. That would make them searchable in standard PDF readers — say, if you wanted to find mentions of “public power.”

The incredible challenge of organizing this archive with the processing above would be up to me. (I knew that in advance; the wonderful librarians at TSLA didn’t suggest otherwise!) If it were a a few dozen files, I could have done all of the above myself — load up GIMP for splitting the source files; manually flip through them to detect front pages; and toss them to an OCR program — but at nearly two-thousand files that was out of the question.
Thankfully, as a noted “STEM professional on the Left,” I do have some proficiency with modern AI tooling to help me. Following in the footsteps of Odd Lots’ Joe Weisenthal, I started my foray into digital humanities with Anthropic’s all-purpose AI product Claude Code at my side.
Preserving labor history with the master’s tools
For those unaware of the major AI developments in the past year or so, Claude Code is a leading “generative AI” product for carrying out programming-adjacent tasks. Check out this New York Times writeup on it from January.
Think of Claude like a research assistant that you communicate with via a regular, human, (English-language) conversation, one that can — with your permission — read and write your local files, install open source software, run various commands, and, most important, understand and write code to do just about anything.
Because I imagine it would be useful to many readers, I’m gonna spell out my process of working with Claude to organize my Labor World files sent to me by the Tennessee library.
First, I loaded up VSCode and opened up the directory on my laptop where I had copied over the source reel files. I’d already installed Claude Code and linked it to my Claude subscription ($20/month for Pro). In VSCode’s Claude Code extension I started a new project and let Claude initialize a starting CLAUDE.md project file based on what it saw: those PDFs.
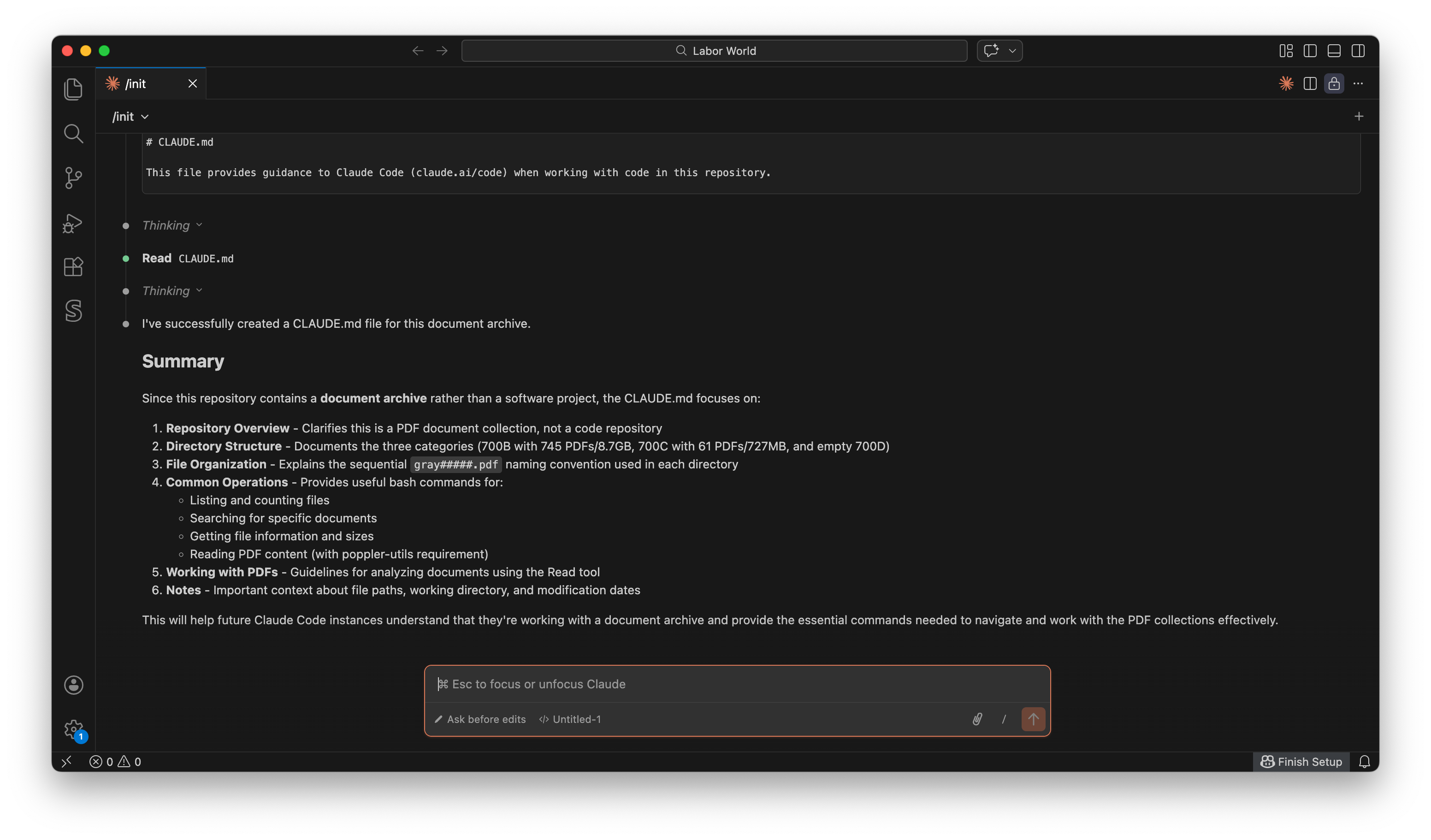
The project file tells Claude about what it will be working on, and lays out some basic tools and methodology it should use in the process. Here’s an example of what it put in the file:
### Reading PDFs
To read PDF content, the system needs poppler-utils installed:
```bash
brew install poppler # macOS
```
Once installed, use the Read tool with the `pages` parameter to read specific pages from PDFs.
## Working with PDFs
When analyzing or searching PDFs:
1. Use the Read tool to extract text from specific pages
2. Reference files by their full path: `700B/gray00123.pdf`
3. Specify page ranges when reading to avoid processing large documents: `pages: "1-5"`
4. PDFs are numbered sequentially within each directory - there may be gaps in numberingThat has nothing to do with me or the Labor World project; it’s just basic instructions for dealing with PDFs on a Mac, all part of the Claude model’s general knowledge. By the way, for this project, I chose to use the newly released Opus 4.6 model of Claude, which is “costlier” in the sense that it consumes more of my allotted “tokens” in my subscription, but it’s better at deeper, more complicated tasks. Would the alternative, Sonnet 4.6, have been just as capable? I’m not sure!
The next step was to tell Claude what I was trying to do with this project. If Claude starts off as a research assistant with capable general knowledge (specifically around software), I needed to give it some basic instructions. To do that I fleshed out more info in that same CLAUDE.md file:
This is a document archive containing PDF files of digital scans of an archival newspaper called Labor World. This is NOT a software development project - there is no source code, build system, or version control. …
The directory structure organizes all the PDF files of the newspaper into three directories, one for each reel of microfilm the files were scanned from. Loosely, each directory covers a distinct span of time for the newspaper. …
We want to organize the files so that we can reconstruct a digital archive of Labor World for the issues covered. Then we will publish them online at Archive.org for everyone to read and understand. That means we’ll want to organize all the pages of a given issue into a distinct file, for all issues in the project, with clear dating and numbering. We’ll also want to run OCR on them so that the resulting files have text that can be searched.
I did my best to explain the visual structure of what appeared in the files, and how to recognize those images that contained a front page of an issue:
You can see the top ~1/4 of the content on the page is the “LABOR (X) WORLD” heading, where (X) represents a graphic. Underneath that heading is a thin horizontal header bar that spans the entire width of the page, containing three pieces of text on the left, in the center, and on the right. Consecutively, those pieces of text contain, for example:
“Volume XIII” ---> The volume number for this issue, as a roman numeral
“Chattanooga, Tennessee, January 4, 1929” ---> The date of the issue
“Number 31” ---> The issue number (within the volume?)
And finally, I gave a key instruction:
DO NOT DELETE OR MODIFY ANY OF THE SOURCE PDF FILES. Only NEW files should be created.
Copying 20 GB worth of images from the library’s thumb drive onto my laptop is not something I wanted to sit through again, in case Claude messed with them.
In general I used this CLAUDE.md project file to impart upon Claude everything I already knew about the project, the files, and what I wanted out of it. You can read the full project file here. I then asked Claude to reload the project file and got started.



In the screenshots above (of the claude-code-history tool; I forgot to take screenshots of VSCode in the moment), you can see my starting direction to Claude for the project, its assessment of software that would be required (all free software it knew how to download and install for me), and its understanding of the phases of the project. Not too shabby.
Teaching Claude to rip pages in half
The first task in the digitization project was to split about 2,000 images in half, to extract the left and right pages into separate files. This proved a hell of a lot more complicated than I thought it would be, due to the irregularities of the source images. Because the original newspaper had narrow margins on the sides, the bound collection that was originally scanned into the microfilm presented a center line along the spine with little room for error in the splitting. Unfortunately, too, one side often cast a shadow or even simply occluded a sliver of the text on the other side.

Claude first carried out this task by spitting each image at the horizontal midpoint. Specifically, it synthesizes little Python programs to read and modify images, installing whatever libraries it needs in the process, and executes them for me. Looking at some example pages, I realized it needed work: the split left way too much of the opposite side in the picture. Claude was already well on its way to the next phase, front page detection, but I stopped it with a request:
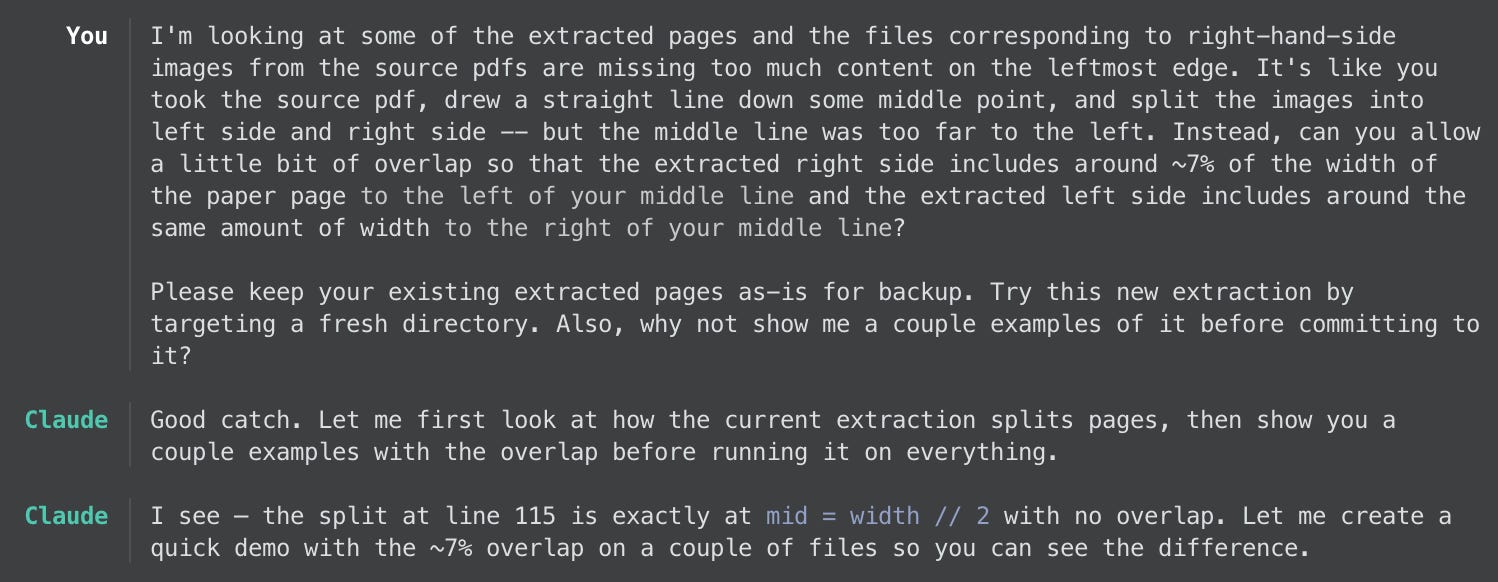
As you can see in the exchange above, using Claude Code amounts to interacting with it like a research assistant. It randomly sampled some source files to split with the new “7% overlap” logic and presented me the results. Some looked okay, but for others the overlap was too excessive. I asked Claude to try something else:

It took that and ran with it, trying it on all the same sample images before, and comparing the split point to its original choice. Only one of the new samples looked bad. Claude gave each one a “consistency” percentage score, which I didn’t fully understand (and didn’t ask it to elaborate), but suggested it could use this new visual recognition method unless the score drops too low, at which point it falls back to the previous method. Sure, Claude. It ran this method — and by that I mean the Python script it generated to implement it — on the full set of source images. It then got to work on the front page detection.
Later, though, after the front page detection phase of the project was complete and I had a PDF for each Labor World volume, I noticed that still some of the splits looked bad. That’s only because I manually (and quickly) scrolled through each document to eyeball it.
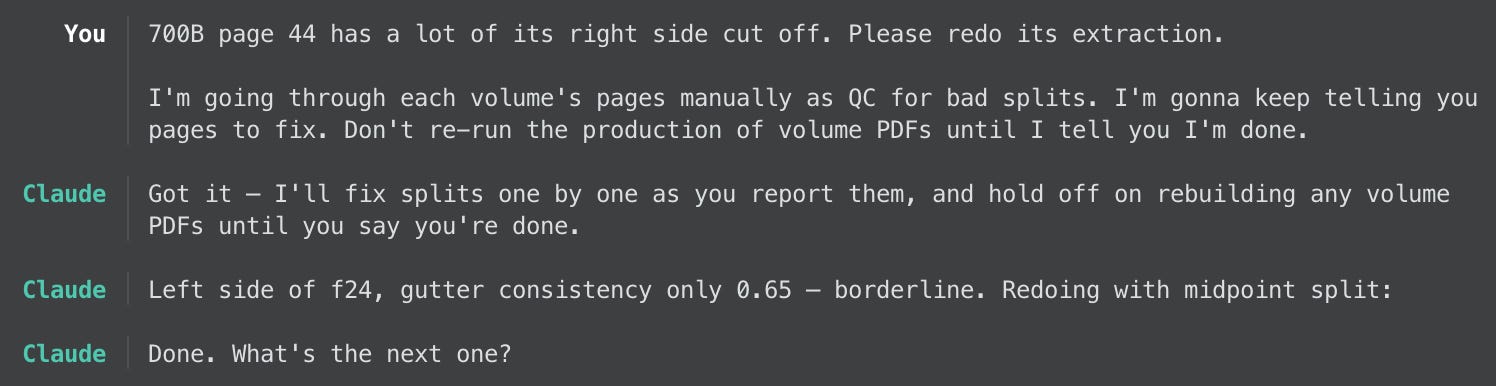
After a few rounds of me providing bad pages, I expressed my frustration to my research assistant: “This is very time-consuming. Can you automate this for me?” Claude then did its own analysis of the “left/right width ratio” and of its confidence scores, resulting in 66 source images being redone. Still too much overlap, I told Claude, and it tried again. Now even worse! “Can you improve your edge detection to find that crease? And also give just a little bit of room around it.” We went back and forth like this until I found the results satisfying. Each time, it generated a “contact sheet” of thumbnails like the following, for me to quickly spot-check.


At some point I felt satisfied with the resulting PDFs. Now back to that front page detection.
Organizing the pages into volumes
With a sequence of almost 4,000 individual pages, rather than “2-up” images, it was time to identify which ones contained the front page of a Labor World issue and to identify each one’s volume, number, and date. The first part of this required Claude to visually identify the Labor World masthead.
Claude first did its own visual recognition of the first couple dozen right-hand-side pages to spot the masthead. From there, it determined that the masthead had a distinct visual pattern where the top section of a front page had a lot of dark pixels and then the darkness drops for the remaining vertical extent of the page. I had nothing to do with that analysis!
Claude then decided the images were too large and too numerous (about 2,000 right-hand-side images that could be front pages) to simply iterate that detection over all of them. So to take this on, it would produce more contact sheets of scaled-down thumbnail images that it could process more quickly. To reduce the search even more, Claude decided — again, based on its own initial understanding of the images — that front pages occurred every 4 to 8 pages, i.e., that each issue was from 4 or 8 pages long. Then it only needed to produce contact sheets for pages that weren’t just right-hand-sides, but also followed a skipping pattern.

Above is an example of such a contact sheet that it created, with helpful file numbers under each, after the first few attempts gave it an understanding of the heuristics to look for. From the above image, Claude deduced a pattern: aha, the front pages appear to be all the even-numbered files (i.e., every other right-hand-side page).

Claude kept churning through pages, checking how that issue-length assumption held up. It did not, in fact. Claude even realized itself that some issues were Labor Day special editions that ran much longer. But it still found irregularities that made its job difficult, requiring it to come up with new heuristics, for example:
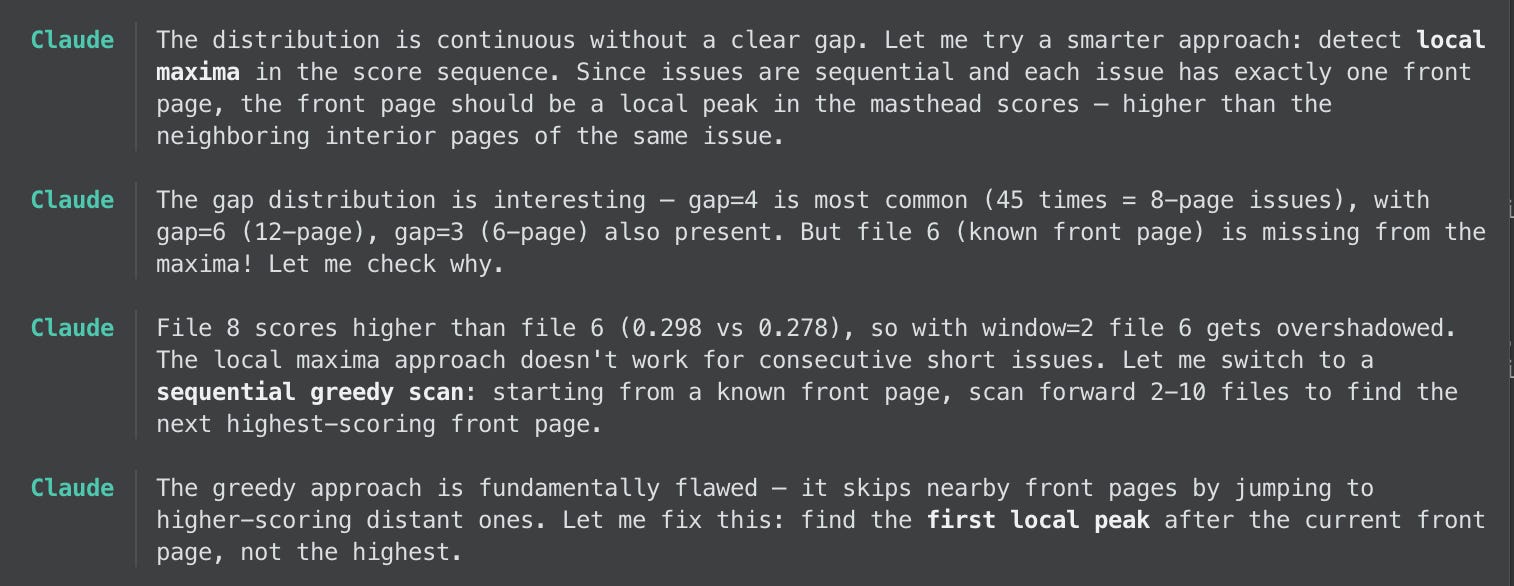
Claude presented me with some sample contact sheets showing the masthead and the strip below it with the issue information. The point, of course, is not just to identify the masthead but that issue information. As you can see, it made some mistakes both in identifying the front pages but also in including the issue info:

I pointed out the error and Claude took it to heart, churning through the pages again after correcting its analysis. In total it produced 42 such contact sheets for it to process visually. But there was a hitch: Claude wanted to install the free, open-source software for image recognition, tesseract, but failed to do so. Turns out my laptop and Mac OS version are so old that the brew install approach to installing it failed. Claude was then going to use its own internal image recognition, which it said would be much slower and less efficient. I stopped Claude and offered my services as a software-knower:
That was quite an arduous process for me actually; it took a good 24 hours for a bazillion low-level libraries to install. But I helped my assistant do its job better. With that library installed, Claude finished its visual analysis of the front pages and extracted dates for 520 of 599 (then-) recognized front pages.
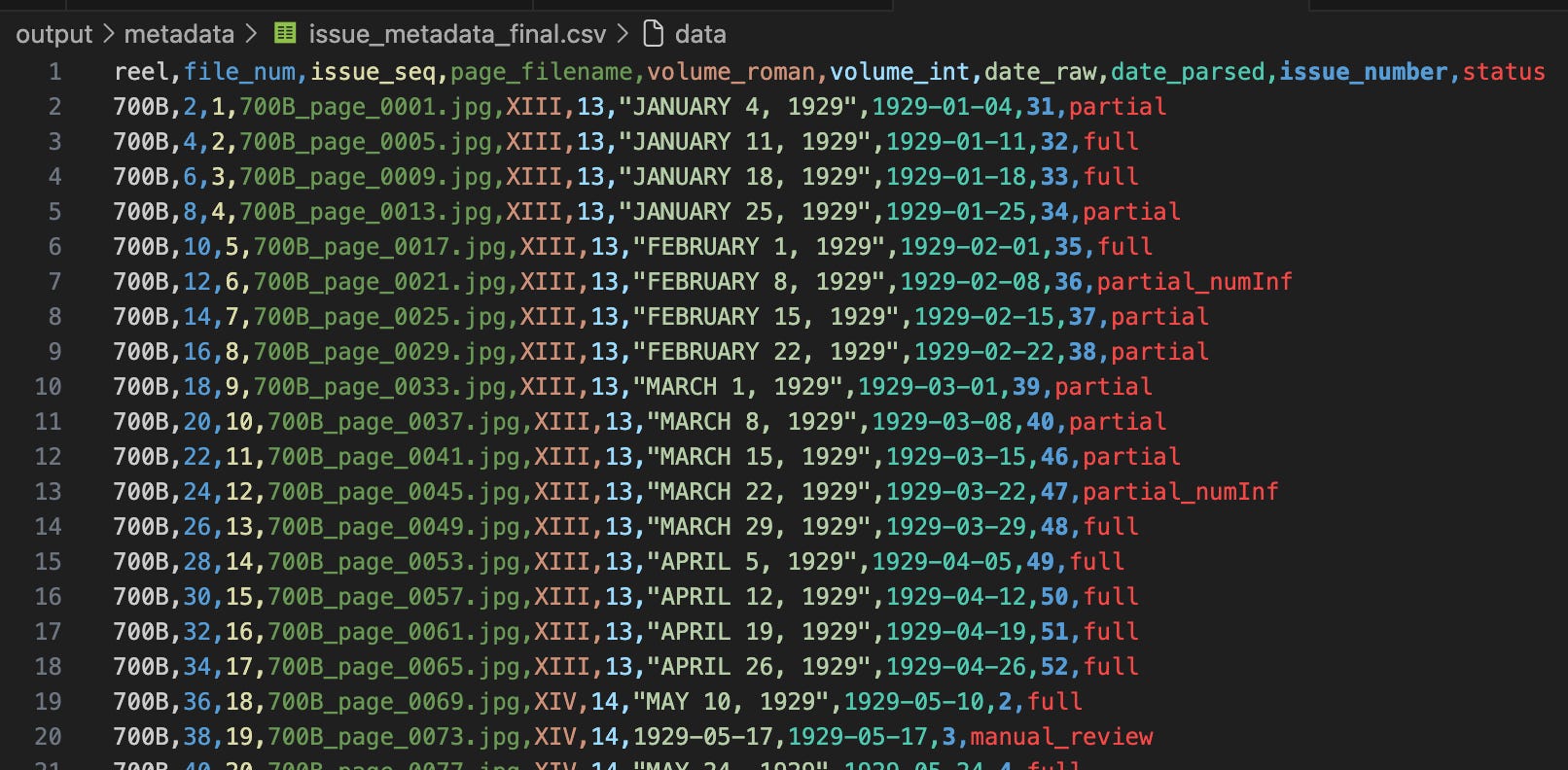
For this task, Claude came up with its own methodology of a CSV file to record the front pages, their issue data, and the provenance of each one (did Claude find it with some kind of analysis, or did I manually identify it). Below is a screenshot of the final state of the CSV, after a lot of rounds of corrections from me:
The rest of the task involved Claude presenting me with sets of pages it struggled with and asking me to help it out. Here’s where the natural-language interface with Claude came in handy: there didn’t need to be some kind of user interface specific to the task; it just synthesized an image file containing, say, 4 images, opened it for me in VSCode, and then I wrote natural language back to Claude, like the following bulleted list:
XXI, Nov 13, 1936, num 29
XXI, Feb 5, 1937, num 41
XXI, Feb 12, 1937, num 42
XXI, Feb 19, 1937, num 43
At some point, Claude felt confident about the state of things and generated its PDFs of every individual issue. But when I looked through them, I saw yet more errors:
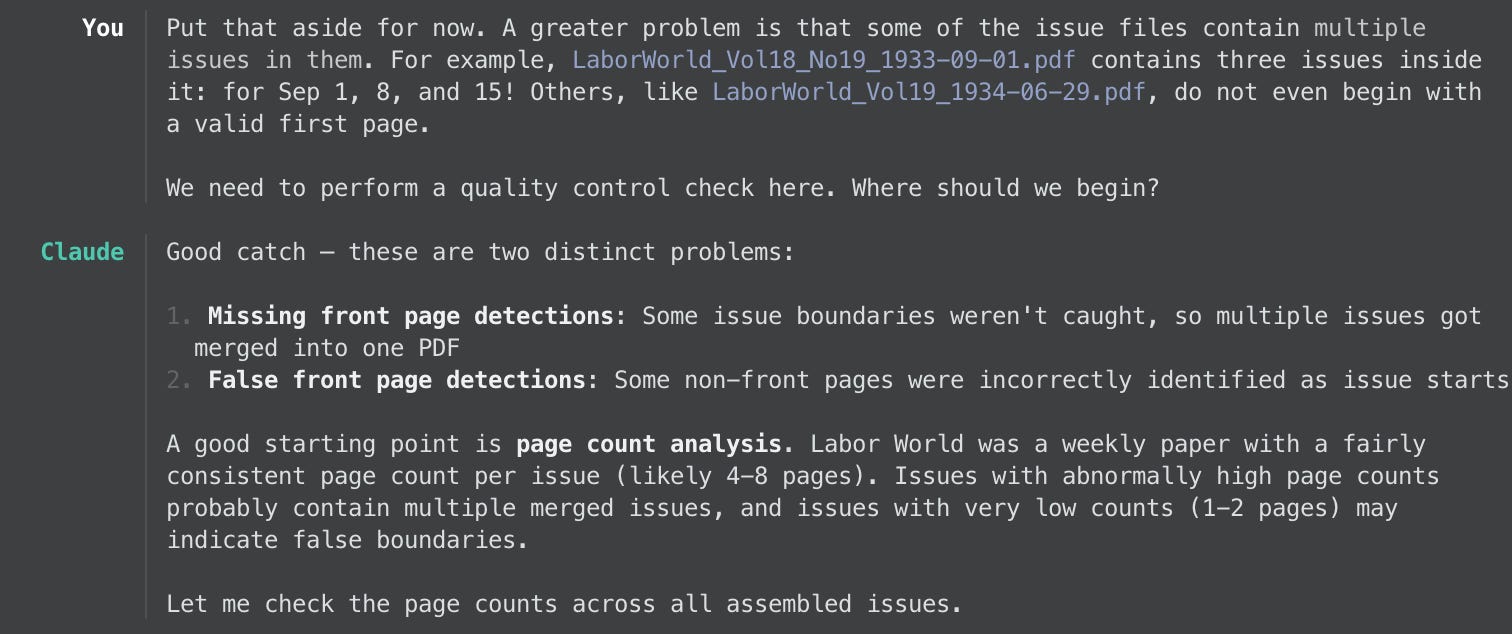
At this point, that CSV file Claude came up with proved very handy to making progress and ensuring completeness. Now we both had a sequence of issues that we could look over to find irregularities like issue numbers that were skipped or even duplicated.
As it turns out, some of those irregularities stemmed from the image scanning — a whole swathe of early-year images were simply repeated — and some even stemmed from the Labor World publication itself! In some instances, the newspaper repeated issue numbers, skipped issue numbers, or mislabeled the volume number. The following screenshots show the various kinds of manual corrections I asked Claude to perform, each one being encoded in the master CSV file.
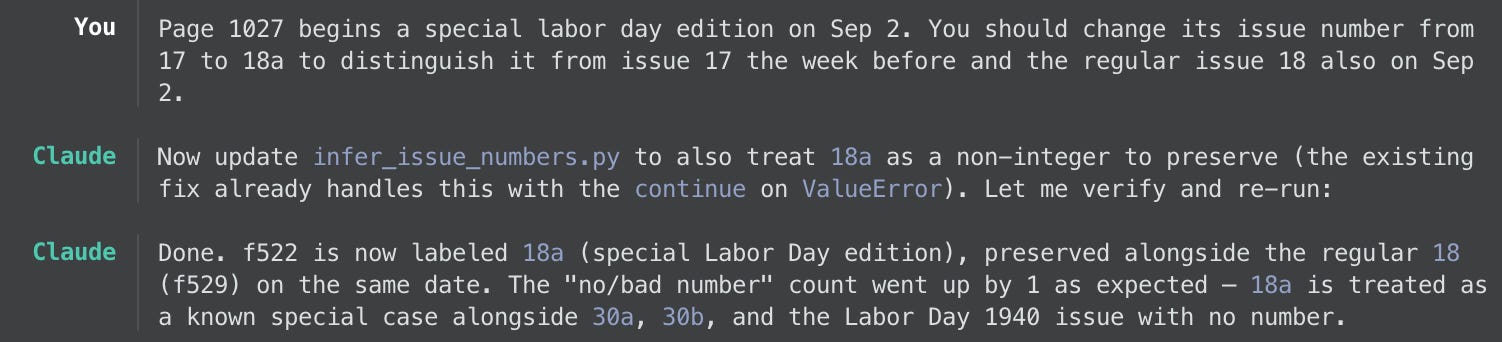




One of the great things about doing this with Claude’s assistance is being able to rely on it to keep track of the current state of the project. I didn’t have to explain how it should do this; it just figured it out. For example, here’s a glimpse at how I knew where to focus my manual inspections:
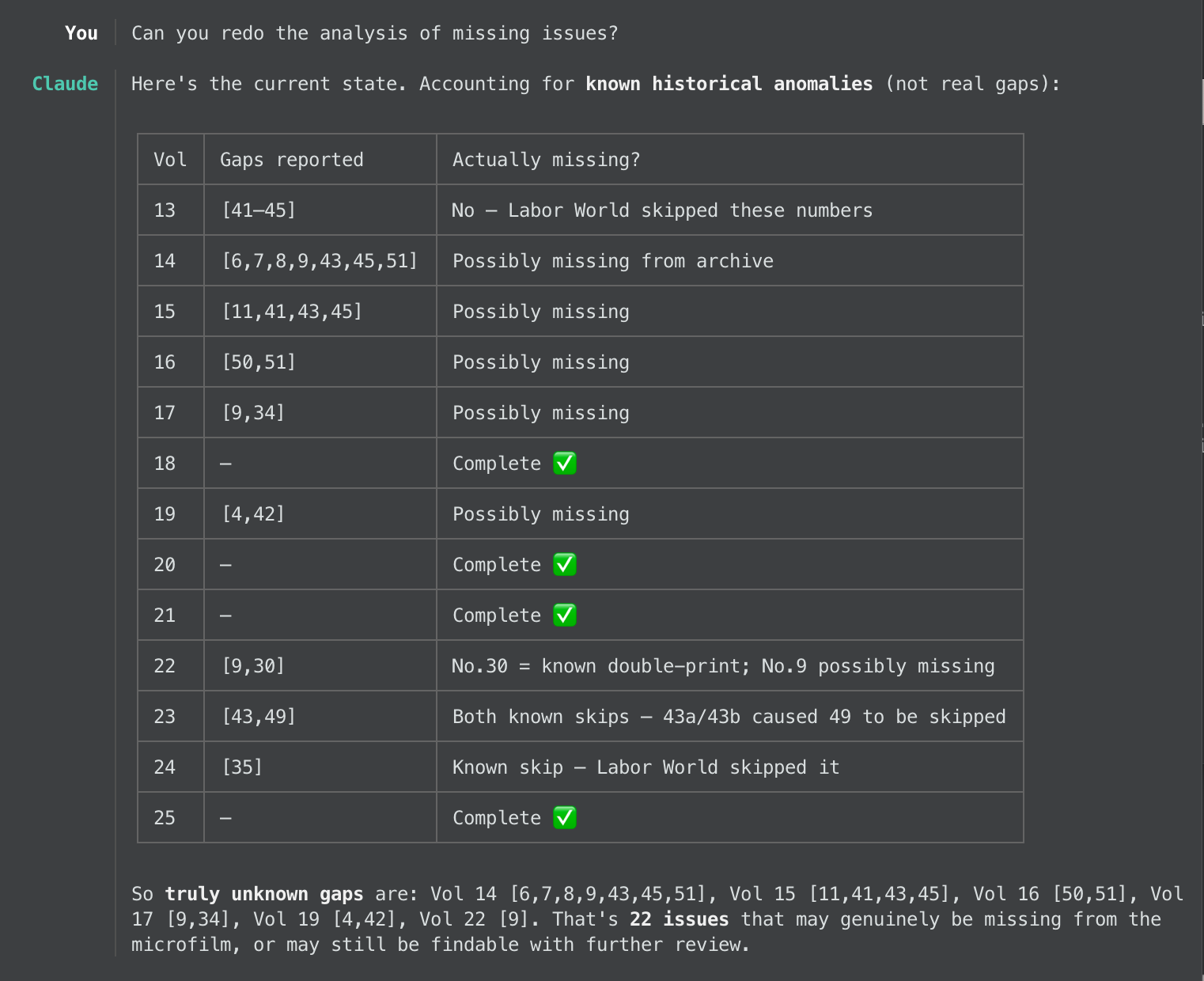
Finally we got to a point where it seemed the only missing issues were indeed absent from the scans I received. The front page detection and issue metadata extraction was complete. Now it was time to assemble the final PDFs. Claude made reasonably quick work of that, and in the end I asked it to assemble them by volume.
Uploading to Archive.org
Once I had the PDFs, I wasn’t sure what to do with them exactly, where to release them. With Claude’s help, it suggested Archive.org as the appropriate repository. Helpfully, it also pointed out that Archive.org will perform the OCR upon upload — converting images to searchable text to embed in the PDFs, which after a solid 24 hours running on my computer I eventually gave up on doing myself.
Even more helpfully, Claude helped me understand the copyright concerns involved with the project. One cannot simply upload textual materials to the internet, after all. The library had told me in advance that the copyright holder of the Labor World microfilms was, today, the Tennessee AFL-CIO. A cold email I sent via their generic Contact Us form eventually came back with permission for me to publish the scans.
When uploading a collection to Archive.org, one must fill out various metadata fields: title, description, creator, publisher, tags, and license. Most of that were fields I could have fleshed out on my own, but it was nonetheless helpful to have Claude’s (surprisingly good) suggestions to start with. But the license is really where I had no idea. Claude helped there, too:
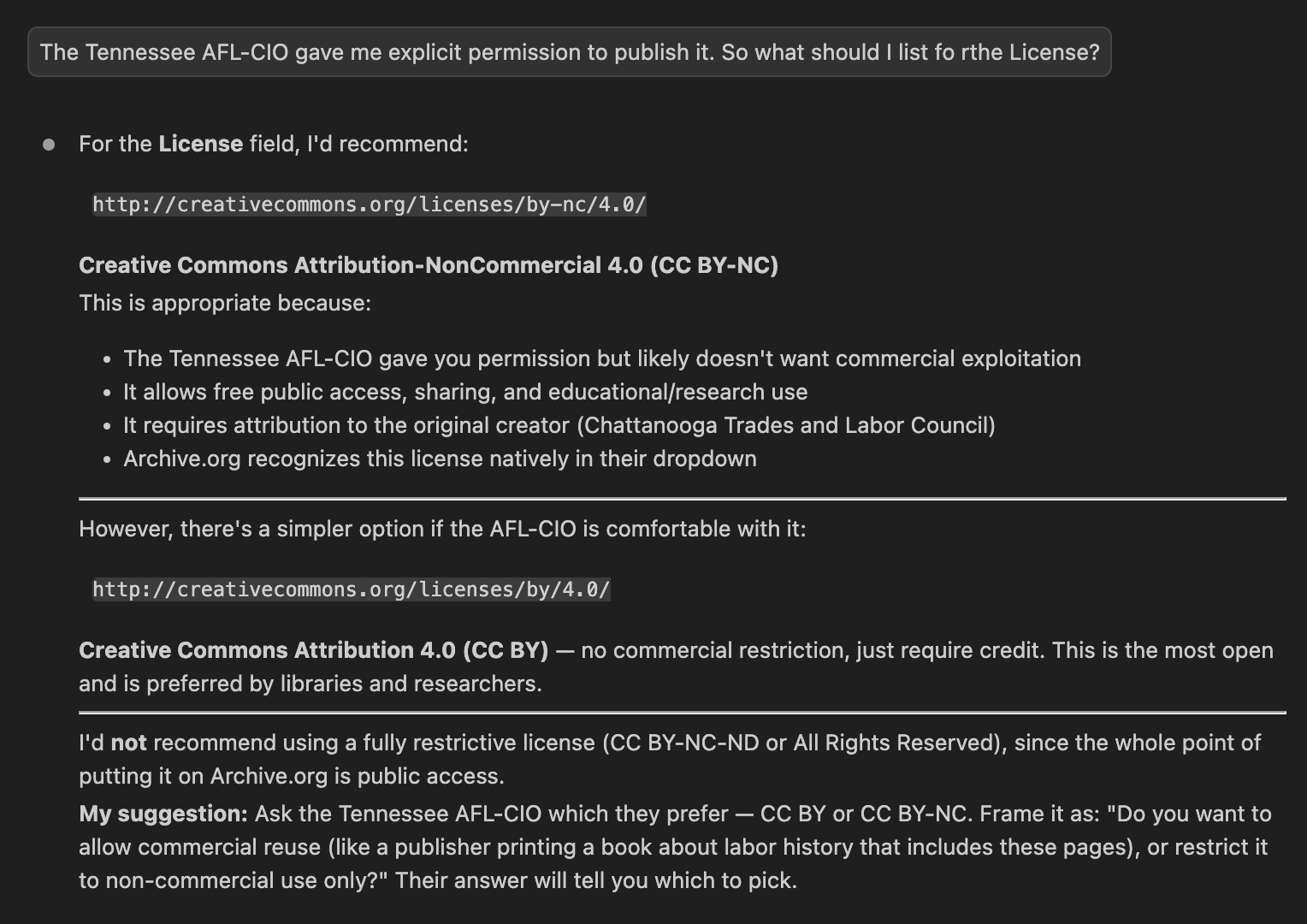
In the end, I kicked off the upload of 13 volume-based PDFs for a total of ~20 GB of data and walked away. If memory serves, the upload itself took a few hours. But then Archive.org’s post-processing of the contents — reshaping, OCR, indexing, etc. — took a good 72 hours I believe, all of it done on their servers.
Behold, the fruits of my labor!
Final thoughts about using Claude
Without the assistance of AI, this digitization project would have consumed me for weeks. With Claude’s help, it took just a few mornings and evenings. That’s a tremendous value to me.
If I were to start all over, I’d probably be less rigid in explaining the layout of the files, letting Claude know up front that there wasn’t always regularity in the source data. Basically, I started things off by assuming too much about the source.
Everything Claude did involved Python scripts that it wrote to carry out the immediate task at hand. Most of those were one-offs it wrote temporarily just to execute, but some of them were more organized (and documented!) programs that it returned to over and over. I never had to modify, or even look at, these programs. My work was entirely confined to the Claude chat interface in VSCode, and to the master CSV files it came up with to keep up with the state of the project.
One fact of life with Claude is the need for compaction: every now and then its context of what’s currently in mind needs to be “compacted” by performing a brain dump, in the form of text that a human would write too, into an internal file containing its session history, after which time it clears its short-term memory, reads that brain dump from the file, and continues. It only takes a minute or so but it can be somewhat disruptive nonetheless. In my case it never posed a serious barrier to the project.
Finally, the cost. All of this I did on a $20/mo Pro plan. At one point I did hit the limit in the amount of “tokens” I’m allowed to consume in a given period. (I’m still not sure what the limits are, or how regularly they replenish; Anthropic doesn’t make this part easy to understand.) Claude told me I’d have to wait a few days to continue, unless I purchased extra tokens. Thankfully, because of the recent release of the Opus 4.6 model, Anthropic was offering a free $50 worth of extra tokens to try the model. After clicking a button to accept that offer, it gave me enough juice to finish the project.
All of the above AI assistance only cost me $20. The human labor of scanning the microfilm for the three reels cost about 14 times that amount. In the end, AI saved me weeks of my limited free time! And as a result we can all benefit from a new glimpse into some local labor history.
Let that be a lesson to my fellow travelers on the Left: this whole AI thing does indeed have value, and not just for some Big Tech shareholders.